

Sinais do Futuro #14 - O joguinho que mostra que a IA não consegue aprender “do zero”
Será que você consegue bater a IA? Link no texto!

Há algumas semanas, o ARC Prize Foundation lançou o ARC-AGI-3, descrito como o primeiro benchmark interativo de raciocínio para agentes de IA. A premissa é simples: colocar sistemas de inteligência artificial em ambientes de jogo desconhecidos, sem regras explicadas, sem objetivos declarados, e medir se eles conseguem descobrir o que fazer. Exatamente como um ser humano faria.
Os resultados foram surpreendentes, considerando o que tantos ditos especialistas projetam e prometem com a IA. Saber o que a IA consegue efetivamente fazer (e não fazer) é fundamental para aplicá-la de forma estratégica e adequada na sua empresa.
O que o benchmark mede
O ARC-AGI-3 é o primeiro benchmark de raciocínio interativo para agentes de IA (clique no link e jogue!), em que humanos e IAs jogam e precisam aprender em ambientes completamente novos, sem instruções claras. Ele avalia se um agente consegue aprender as regras de um ambiente desconhecido explorando-o e obtendo feedback do resultado de suas ações neste ambiente.
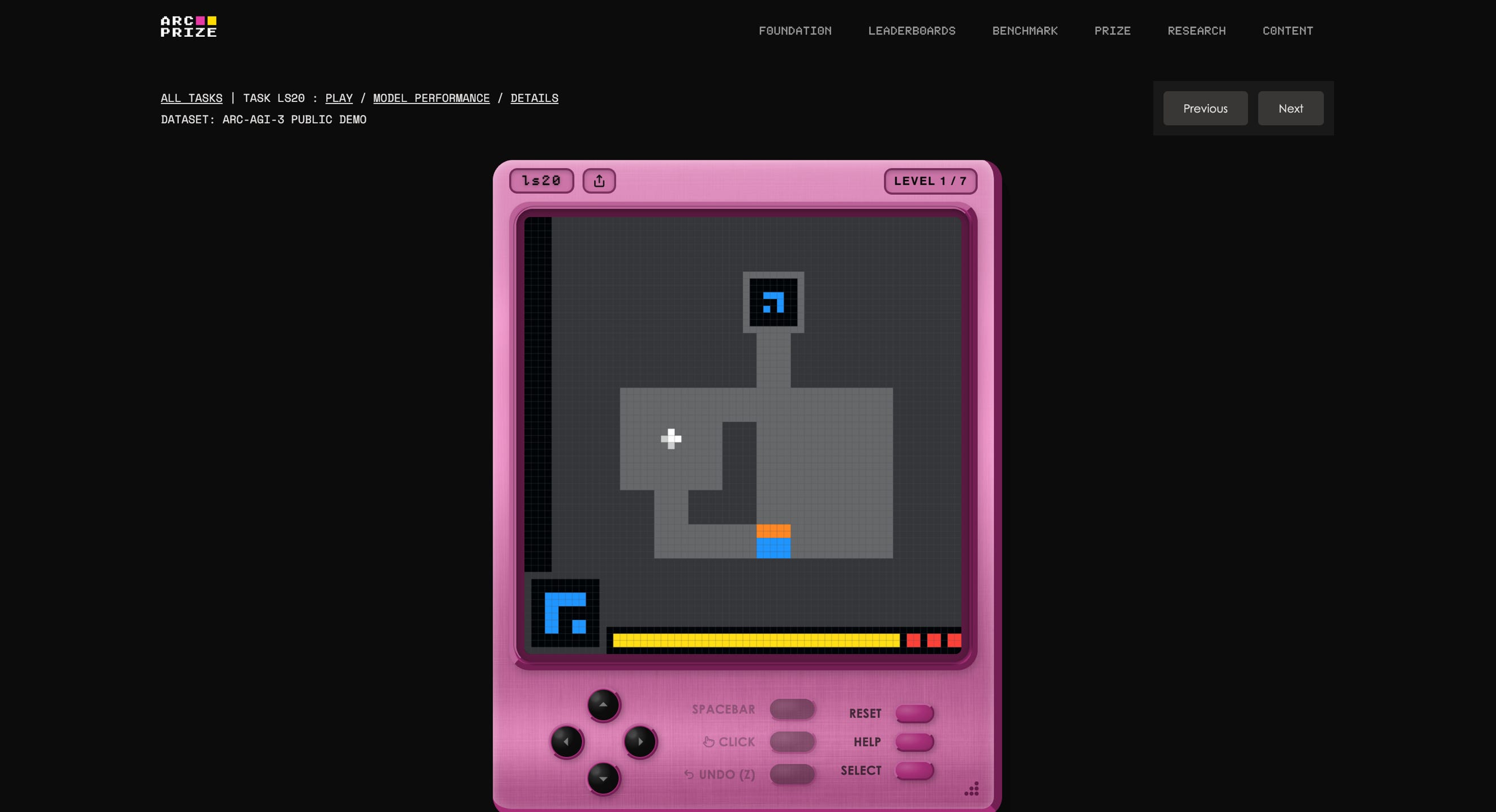
Cada ambiente é 100% solucionável por humanos e testadores humanos os concluem em mediana de aproximadamente 7 minutos e meio. Os modelos mais avançados disponíveis hoje, como Google Gemini 3.1 Pro, OpenAI GPT-5.4 e Anthropic Opus 4.6 chegaram no máximo a 0,37% (Gemini) de eficiência. Detalhe para o Grok, que conseguiu 0% (leia a nota de rodapé se quiser entender melhor os critérios desse cálculo de eficiência).1
A confusão que o mercado alimenta
Nos últimos dois anos, CEOs de grandes empresas de tecnologia têm feito afirmações ousadas. Jensen Huang, CEO da Nvidia, declarou recentemente que a inteligência artificial geral já foi alcançada. Afirmações semelhantes circulam em painéis, conferências e releases corporativos com frequência crescente. Vale pensar se são afirmações genuínas ou se são motivadas por um conflito de interesses, que surge da própria intenção de aumentar o valuation de suas próprias empresas em novas rodadas de captação de investimentos.
O ponto que poucas manchetes e pessoas explicam com clareza é que os grandes modelos de linguagem não aprendem durante o uso. Eles foram treinados em volumes imensos de dados antes de chegarem ao usuário, e esse treinamento não muda enquanto você conversa com eles. O que parece adaptação é, na prática, recuperação sofisticada de padrões. Quando alguém diz “a IA já aprendeu a fazer X sozinha”, quase sempre está descrevendo uma capacidade treinada previamente e não algo que o sistema descobriu por conta própria em tempo real. Você está apenas acessando este conhecimento e não está ensinando uma máquina.
O que significa “aprender” para uma IA
O ARC-AGI-3 foi projetado exatamente para desafiar as IAs e ver o que acontece quando elas não usam esses atalhos de memória. Seus idealizadores conseguiram isso criando um ambiente interativo e mecanismos autônomos de descoberta de objetivos. Dessa forma, conseguem testar como a IA se comporta quando não há padrões de treinamento, e qual a diferença de desempenho em comparação com a adaptação natural do processo de aprendizado humano.
O desempenho abaixo de 1% dos modelos de ponta indica uma incompatibilidade entre as arquiteturas de IA atuais e os processos cognitivos necessários para verdadeira adaptação a tarefas novas. Apesar de seu crescimento exponencial e do surgimento de capacidades avançadas de raciocínio, sistemas como GPT-5.4 e Gemini 3.1 Pro ainda falham em ambientes que humanos sem treinamento (mesmo crianças) navegam com sucesso.
Será que você consegue bater o Gemini?
O ARC Prize disponibilizou versões jogáveis do benchmark diretamente em navegadores. Acesse uma das tarefas aqui e veja quanto tempo você leva para descobrir o objetivo e concluir o ambiente. A maioria das pessoas consegue em alguns minutos. Nesse joguinho específico do link, o desempenho de ChatGPT 5.4, Gemini 3.1, Grok 4.20 e Claude Opus 4.6 foi 0%. Se você tiver mais curiosidade, role a tela para baixo e veja o replay do humano de referência (e fique agoniado porque acho que não foi a mais esperta das pessoas...).
O que isso significa
Nada aqui diminui o valor real das IAs atuais. Sistemas como Claude, GPT e Gemini são extraordinariamente úteis para tarefas dentro do domínio do que já foi aprendido durante o treinamento.
Mas a confusão entre “executa bem tarefas conhecidas” e “aprende autonomamente em tempo real” tem consequências importantes para tomada de decisões estratégicas. Empresas que constroem planos supondo que terão IAs que descobrirão sozinhas o que precisam fazer em novos contextos estão trabalhando sob uma visão arriscada.
Esse experimento só reforça que a IA ainda é pouco eficaz em contextos genuinamente novos, sem uma grande quantidade de dados de referência e sem orientações claras. Por isso, a organização e estruturação de bases de dados e a capacitação das pessoas para definir objetivos claros e direcionar as interações com a IA são competências cujo desenvolvimento é inadiável para todas as organizações.
Quer explorar como preparar a sua organização para múltiplos futuros possíveis? Me manda um e-mail em fernando@deltaconsulting.com.br.
Para não perder atualizações, acompanhe novas reflexões também em meu perfil no LinkedIn.
Uma observação importante sobre esses os percentuais de eficiência: eles não significam que as IAs resolveram 0,4% das tarefas ou menos. O sistema de pontuação, chamado RHAE (Relative Human Action Efficiency), funciona assim: para cada nível completado, a pontuação é calculada pelo quadrado da razão entre o número de ações do segundo melhor humano de referência (o segundo melhor desempenho de dez pessoas comuns aleatórias) e o número de ações da IA.
Se o humano usou 10 ações e a IA usou 20, a pontuação é (10/20)² = 25%. Com 30 ações da IA, cai para (10/30)² ≈ 11%. Com 40 ações, (10/40)² ≈ 6%. Se a IA ultrapassar cinco vezes o número de ações humanas, a tentativa é encerrada automaticamente com pontuação zero.
A pontuação final é uma média ponderada entre todos os níveis, com os níveis mais avançados contando mais, e depois entre todos os ambientes do conjunto de avaliação.
O 0,37% do Gemini representa essa média: na maioria dos ambientes as tentativas foram encerradas por limite de ações sem nenhuma solução; nos poucos casos em que houve progresso, a eficiência foi tão inferior à humana que a pontuação acumulada chegou a essa fração residual.